OTR Toolkit User's Manual
Last modified: June 09, 2015
This documentation is for those, who want to use the toolkit for tablature recognition, but are not interested in extending its capabilities.
Overview
As every historic tablature print uses different tablature symbols, you must first train the system with some pages of lute tablature and then use this training data for subsequent recognition:
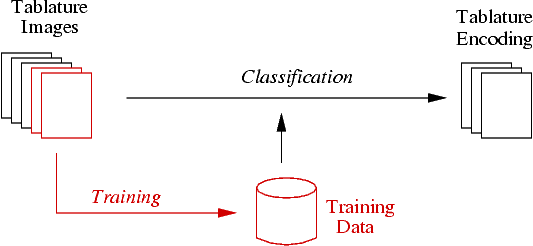
Hence the proper use of this toolkit requires the two following steps:
- training of the tablature symbols on representative tablature images. This step is interactive.
- recognize the tablature images with the aid of this training data. This step usually runs automatically without user interaction.
Usage Options
There are two options to use this toolkit: you can either use the toolkit out-of-the-box, or you can build your own scripts with the aid of the python library functions provided by the toolkit. Both options are described in detail below.
In any case, the output of the recognition process is a tablature or music encoding in the abc format.
Output Format
The abc format was originally invented by Chris Walshaw as a simple ASCII notation for folk tunes. Meanwhile it has been extended by many people to encode a wide variety of music notation. In particular, Christoph Dalitz extended abc to support the notation of lute tablature.
Not every software listed on the abc home page supports all abc extensions. The abc tablature encoding generated by this toolkit is specific for the program abctab2ps, because this is the only abc program which supports lute tablature. See the user's guide of this program for a detailed description of the format.
The abc music transcription however is abc standard conformant and thus should be readable by any abc program. For instance you can use abc2midi to generate a MIDI for "proofhearing" the recognized tablature.
Using the toolkit out-of-the-box
The toolkit provides ready-to-run functionality for all tasks of optical tablature recognition:
- the script otr_prepare.py for preprocessing (optional)
- Gamera's interactive training dialog for training
- the scripts otr_recognize.py and otr_german_recognize.py for recognition
Preprocessing
Preprocessing can be done interactively from the image contextmenu entry OTR/preprocessing. As this is a cumbersome way to preprocess a batch of images, there is otr_prepare.py as a wrapper script for some plugins. Example:
otr_prepare.py -smooth -deskew -depict scan.tiff -o prepped.png
This will read the file scan.tiff, perform deskew, smoothen and remove_pictures on it and saves the result to prepped.png.
For a full list of possible command line options with an explanation, call otr_prepare.py -?.
Note
If you choose to use some of the routines from the preprocessing plugins, make sure you use the same preprocessing for both training and recognition.
Training
This toolkit provides a special method for starting the training dialog because the training description in the Gamera documentation cannot be directly applied to this OTR toolkit for two peculiarities of lute tablature recognition:
- you cannot use the "Image" menu entries like "Open and segment image", because all symbols in the tablature image are connected by staff lines so that a CC based segmentation fails
- you cannot enter arbitrary symbol names but must adhere to certain conventions
The method described below takes care of these points because it removes the staff lines before segmenting the image and when it opens the classifier window, it loads an appropriate symbol name list.
Starting the training dialog
As training is interactive, you must start the training dialog from gamera_gui with the following steps:
- From the top menu "Toolkits", choose "otr/import 'otr' toolkit". This will import the toolkit and create an icon for it in the icon list on the left side.
- Right click on the toolkit icon and select from the context menu "Train French/Italian Tab Page" or "Train German Tab Page", depending on your tablature type
When training a French/Italian tablature page, the following options dialog appears (the dialog for German lute tablature is similar):
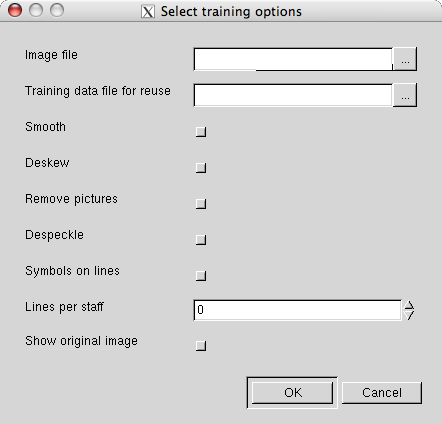
Here you can select an image file, and choose preprocessing options. The other options have the following meaning (the last three options are absent for German tablature, because it does not use staff lines):
- Training data file for reuse
- Not useful for training the first page, but for subsequent pages you can enter your training data file.
- Symbols on lines
- Check this when the tablature symbols are printed on the lines rather than between, because this requires a different approach to staff line removal.
- Lines per staff
- When zero, the number is automatically guessed. Some staff removal algorithms however require this number beforehand and some work more reliable when this number is given.
- Show original image
- When checked, the original image (after preprocessing, but before staff removal) is displayed in the training dialog window for better orientation. When unchecked, the image after staff removal is displayed, which suits better when the staff removal algorithm distorts the image considerably.
Note
When you check some preprocessing options, make sure to use the same preprocessing options on all training images and later in the recognition phase.
The image will be segmented, which may take some time because it includes a staff removal step. The original image (with staff lines) will be displayed in a classifier window together with the default symbol list used in this toolkit.
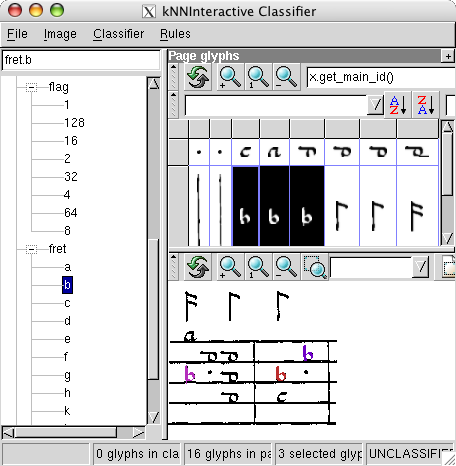
Note
All symbols appear twice in the symbol list on the left: with and without the prefix _group. Make sure you use the right versions during manual classification, i.e. the _group class name for fragmented symbols and the plain class name for unfragmented symbols.
From hereon you can follow the training tutorial in the Gamera documentation which describes how to classify symbols and how to save the training data and merge the training data from several images into a single training database. The possible symbol names are described in the next section.
Note
For training another image do not use the menu "Image/Open and Segment image"! Instead you must close the classifier window and use the toolkit icon context menu again.
Classifier Symbol Names for French and Italian tablature
The postprocessing routines in TabGlyphList and in otr_recognize.py rely on the glyph names given in the table below.
| Symbol Class | Description |
|---|---|
| fret.a, fret.b, ... | Fret letters or numbers. Note that you must use letters even in italian tablature and that the letter j is not used so that the 9th fret is fret.k. Hence the glyph "2" is trained as fret.c in italian or guitar tablature and the glyph (actually a group) "11" is fret.m Special symbols for diapasons can be trained as fret.a8, e.g., for the empty 8th course. |
| flag.1, flag.2, flag.4, flag.8, ... | Rhythm flag for a whole note, half note, quarter note etc. It does not matter whether these are the real time values, essential is only their relative quotient. |
| fermata | A fermata. |
| bar | Bar line. It is possible to differentiate, e.g. with bar.double or bar.repeat; in that case the symbol interpretation will ignore anything after the first dot. Note that you will only need to train bar lines when you plan to classify bar lines statistically with Gamera's builtin kNN classifier. If you use the deterministic bar line removal TabPage.remove_barlines, training bar lines or groups (when the bar lines are broken) is of no use. |
| dot | A dot. Dots can have different meanings in tablature (flag prolongation, index finger, repeat dots, ...) which the symbol interpretation tries to figure out and to classify further. |
| deco.star.WHERE, deco.hash.WHERE | A star or hash sign as decoration. To which fret symbol it is attached depends on the modifier WHERE: when WHERE is left or right, it is attached to the fret symbol on the left or right, respectively. When WHERE is here, it is considered as a symbol on its own that replaces a fret letter. |
| time.c time.c_cut time.3 | mensural sign |
| *trash* ('*' stands for any string) | Glyphs that should be ignored. These will be removed by otr_recognize.py from the glyph list |
You can train other additional names, eg. tenuto signs as deco.tenuto. These names will be kept in the glyph list and sorted by TabGlyphList.set_glyph_properties(), but are ignored by the postprocessing routines which create abc output. You will need to write your own postprocessing for them; see the developer's manual for an example.
Note
Occasionally, one realizes at a later point that the rhytm flags shoud be interpreted in a different way. It may be that what seemed to be sixteenth notes actually are quarter notes, etc. For this situation, there is a script otr_factor_training.py in the subdirectory scripts for automatically changing all rhythm lengths.
Classifier Symbol Names for German tablature
The postprocessing routines in GermanGlyph and in otr_german_recognize.py rely on the glyph names described below.
| Symbol Class | Description |
|---|---|
| fret.c1.f0, fret.c1.f1, ... fret.c2.f0, ... | Symbol specifies both course and fret. fret.c1.f0 for instance means "fret 0 on course 1". In contrast to tablatures with stafflines, German tablature symbols uniquely specify course and fret. (see below for examples) |
| flag.1.1, flag.2.1, flag.4.2, ... | Rhythm flags with the numbers specifying the time value and the number of grid stems. It does not matter whether these are the real time values, essential is only their relative quotient. (see below for examples) |
| flag.fermata | A fermata. |
| bar | Bar line. It is possible to differentiate, e.g. with bar.double or bar.repeat; in that case the symbol interpretation will ignore anything after the first dot. Note that you will only need to train bar lines when you plan to classify bar lines statistically with Gamera's builtin kNN classifier. If you use the deterministic bar line recognition, training bar lines or groups (when the bar lines are broken) is of no use. |
| bar_part | Fragment of a bar line. |
| dot | A dot. Dots can have different meanings in tablature (flag prolongation, index finger, repeat dots, ...) which the symbol interpretation tries to figure out and to classify further. |
| stroke, higher_fret | Horizontal strokes have different meanings in German tablature: when over a number it means that this number specifies a fret on the sixth course; when over a character it shifts the fret 5 frets higher. You can thus simply train all horizontal strokes identically and the recogniiton post processing tries to figure the meaning out. |
| *trash* ('*' stands for any string) | Glyphs that should be ignored. These will be removed by otr_german_recognize.py from the glyph list |
As German lute tablature is staffless, the symbols uniquely describe course and fret, which are encoded as fret.fn.cm where n is the fret number and m the course. For a typical German tablature using a Fraktur font, the following symbols are used up to the fifth fret:
| f0 | f1 | f2 | f3 | f4 | f5 | |
| c1 | 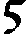
|
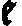
|
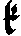
|
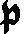
|
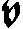
|
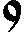
|
| c2 | 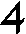
|
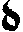
|
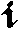
|
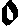
|
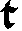
|
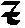
|
| c3 | 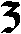
|
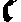
|
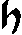
|
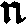
|
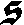
|

|
| c4 | 
|
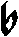
|
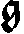
|

|

|

|
| c5 | 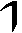
|
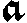
|
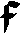
|
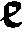
|
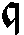
|
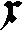
|
| c6 | 
|

|
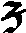
|

|
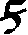
|

|
Some symbols belong to fret/course symbols like, e.g., the asterisk for indicating held stops. Depending on the print source, these symbols appear before, behind, below or above their main symbol. To keep the toolkit flexible, the positioning of such "secondary" symbols can be trained with the modifier keywords left, right, above or below, e.g. deco.tenuto.right for an asterisk belonging to the symbol to its right.
Beamed flags
Concerning rhythm flags, some tablature prints (e.g. German tablature or Phalese) arrange flags in "grids" which can include flags of different time values. For these, we must encode not only the rhythm value as for tablature, but also the number of stems in the grid. This is done with a dot separated list as demonstrated in the following examples:
| Flag combination | Class name | Flag combination | Class name |
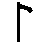
|
flag.2.1 = half note on one stem | 
|
flag.8.4 = eigth notes on 4 stems |

|
flag.2.1.4.2 = half note on one stem followed by two quarter notes | 
|
flag.2.1.4.2.2.1 |
Recognition
There are two scripts for recognition, depending on the tablature type: otr_recognize.py for French and Italian tablature and otr_german_recognize.py for German tablature without staff lines.
French and Italian tablature
otr_recognize.py takes a tablature image and a training data file as input and creates an abc encoding of the tablature as output. For a full list of possible command line options with an explanation, call otr_recognize.py -?.
Here is a description of the most important options:
- -d xml
- training data file in xml format. When you have used some preprocessing options on the training data make sure that you apply the same to the input of otr_recognize.py.
- -onlines
- By default otr_recognize.py assumes that the tablature symbols are printed between the staff lines. If they are printed on the staff lines, use this option.
- -tabtype type
- tablature type. Possible values for type are french (letters with highest chord on top line) and italian (numbers with highest course on bottom line)
- -knnbars
- Use the statistical knn-Classifier also for the recognition of bar lines. Otherwise bars are recognized heuristically with TabPage.remove_barlines; this option skips the call of this function. When you use this option you must have trained bars in the training phase.
- -max_group_parts
- Maximum number of parts considered for grouping by the classifier. A larger number creates a larger search space, thereby slowing down the classification and possibly creating misclassifications.
- -abcmusic
- Do not only write the tablature code, but also an abc music transcription. To specify the tuning, use the option -tuning. The music code is written to the same output file as a seperate "tune". If you want to extract only the music (eg. for feeding it into abc2midi), use abcselect -X 2 on the output file. abcselect is available from the abctab2ps homepage.
- -tuning tuning
- Specifies the tuning for the music transcription with TabGlyphList.to_abcmusic. The tuning is specified from top to bottom with the notes in abc code (sharp = prefix '^', flat = prefix '_'). The default value is "gdAFG," (standard renaissance lute tuning).
German tablature
The recognition of German lute tablature works similar, except that you must use the script otr_german_recognize.py instead. For a full list of possible command line options with an explanation, call otr_german_recognize.py -?.
The most important options are:
- -d xml
- training data file in xml format. When you have used some preprocessing options on the training data make sure that you apply the same to the input of otr_german_recognize.py.
- -knnbars
- Use the statistical knn-Classifier also for the recognition of bar lines. Otherwise bars are recognized heuristically. Note that using this options requires that bars are actually present in the training data.
- -abcmusic
- Do not only write the tablature code, but also an abc music transcription. To specify the tuning, use the option -tuning. The music code is written to the same output file as a seperate "tune".
- -tuning tuning
- Specifies the tuning for the music transcription when using the option -abcmusic. The tuning is specified from top to bottom with the notes in abc code (sharp = prefix '^', flat = prefix '_'). The default value is "gdAFG," (standard renaissance lute tuning).
Writing custom scripts
If you want to write your own scripts for recognition, you can use otr_recognize.py as a good starting point. The following sections describe some aspects of writing scripts not only for recognition, but also for training.
In order to be able to use the OTR toolkit functions, you must import them at the beginning of your scripts with:
# French/Italian tablature (with staff lines): from gamera.toolkits.otr.otr_staff import * from gamera.toolkits.otr.otr_glyph import * # German tablature (no staff lines): from gamera.toolkits.otr.german_page import * from gamera.toolkits.otr.german_glyph import * # all tablature types: from gamera.toolkits.otr.plugins import *
Training
Before we can fire up the training dialog from gamera_gui, we need to do some preparations: load an image, do some preprocessing (optional), remove staves and segment the image.
# load an image and do some preprocessing
image = load_image("tablature.tiff")
image = image.deskew()
if image.data.pixel_type != ONEBIT:
image = image.to_onebit()
# remove staff lines with the TabPage class
# and create a glyph list "ccs" with connected component analysis
tab = TabPage(image, online=1)
tab.remove_staves()
ccs = tab.image.cc_analysis()
When the image has a lot of randomly touching symbols, you will need to add a custom segmentation function here.
Now that we have the tablature symbols isolated in the list ccs, we can pass this list to a classifier and open Gamera's training interface:
# create classifier and start training session classifier = knn.kNNInteractive([], ['aspect_ratio', 'moments', 'volume64regions', 'nrows_feature'], 0) classifier.display(ccs, orig_image, symbol_table)
As this script requires the gamera GUI as its runtime environment (for the interactive training session), it is easiest to execute the script from the python shell in gamera_gui:
>>> execfile("/path/to/your/script.py")
Alternatively you could pass the script file name as a command line parameter to gamera_gui or use the Unix #! magic.
Recognition
The initialization of a standalone script requires some more calls, because in the example above these are called implicitly by gamera_gui:
# general stuff from gamera from gamera.core import * from gamera import knn from gamera.classify import BasicGroupingFunction # otr toolkit from gamera.toolkits.otr.otr_staff import * from gamera.toolkits.otr.otr_glyph import * from gamera.toolkits.otr.plugins import *
The first step in recognition is the same as in training: load an image, do some preprocessing (optional), remove staves and segment the image. From the glyph list we create a TabGlyphList object, which we will need for postprocessing:
# load an image and do some preprocessing
image = load_image("tablature.tiff")
image = image.deskew()
if image.data.pixel_type != ONEBIT:
image = image.to_onebit()
# remove staff lines with the TabPage class
tab = TabPage(image, online=1)
tab.remove_staves()
# create TabGlyphList, glyphs are property "glyphs"
ccs = tab.image.cc_analysis()
glyphs = TabGlyphList(ccs)
Now we can load the training data into a classifier and use it for classifying the tablature symbols. Here we assume for simplicity that bar lines are also recognized statistically with the kNN classifier:
# create classifier and load training database
classifier=knn.kNNInteractive([], ['aspect_ratio', 'moments', 'volume64regions', 'nrows_feature'], 0)
classifier.from_xml_filename("trainingdata.xml")
# classify symbols and group them
# note that grouping does not modify the list, and thus we need
# to add the groups afterwards and remove their parts explicitly
grp_distance = tab.staffspace_height/2
(added, removed) = classifier.group_list_automatic(glyphs.glyphs, \
BasicGroupingFunction(grp_distance), max_parts_per_group=3)
if len(added) > 0:
# remove group parts
glyphs.glyphs = [x for x in glyphs.glyphs if (not x.match_id_name("_group._part.*")]
# add found groups
glyphs.glyphs.extend(added)
Now all individual symbols are identified, but their meaning is not yet known (eg. which glyphs belong together in a chord, to which course a fret letter applies etc.). This semantic interpretation is done with TabGlyphList.set_glyph_properties. Afterwards we can export to abc:
# set the semantic properties (course etc.) of and convert to abc tablature and music code
glyphs.set_glyph_properties(tab)
tabcode = glyphs.to_abctab()
musiccode = glyphs.to_abcmusic(tuning="gdAFCG,", factor=1)
# write abc code to a file
abc_file=open("song.abc", "w")
abc_file.write(tabcode)
abc_file.write("\n\n")
abc_file.write(musiccode)
abc_file.close()
Now you have a file song.abc containing the tablature code and a music transcription in abc. You can create a nice looking postscript file from this with abctab2ps and create a Midi file from the music transcription with abcselect and abc2midi:
abctab2ps -O song.ps song.abc abcselect -X 2 song.abc > music.abc && abc2midi music.abc -o music.midi